
( last updated : April 27, 2020 )
Python
https://github.com/cao-weiwei/
学了Python基础语法后想锻炼一下解决实际问题的水平,那本文介绍的小项目刚刚好。通过本文中项目,你可以学会不打开12306或者APP就能查询火车票,同时熟悉Python库的使用方法,了解Python程序设计思路。
这个项目来源于此处,本文是在学习后进行的总结,最终效果如图所示。
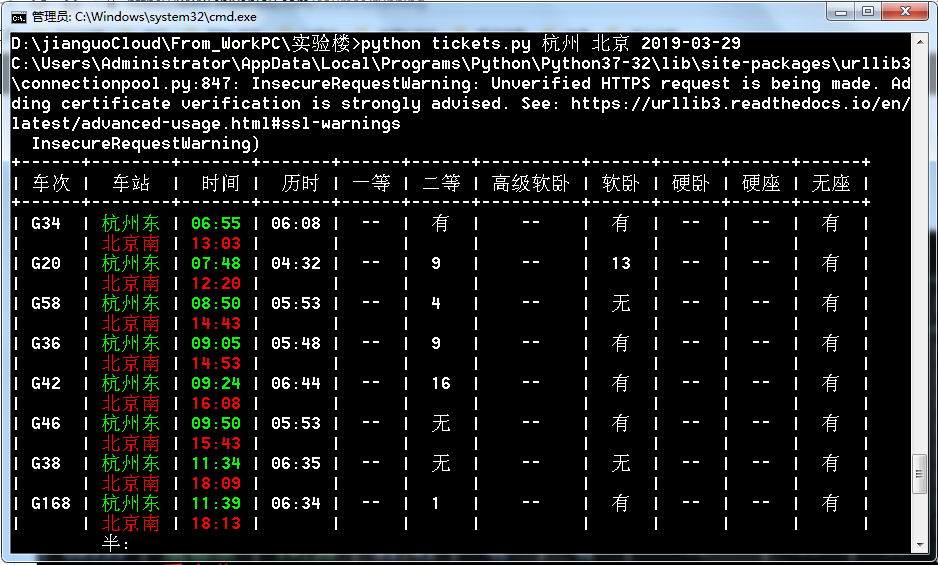
本项目需要Python基础语法知识,在项目中可以学习到如下内容:
docopt、requests、colorama和prettytable库的使用Python库为了实现如图所示功能效果,我们需要先进行需求分析。
这样,总结下来可以分为如下几个大的模块
Python库docopt库:终端命令行参数解析器,查看详情;requests库:简单易用的Python HTTP库,快速上手文档;prettytable库:格式化输出打印内容,查看详情;colorama库:命令行着色工具,查看详情;通过如下命令一键安装以上资源:
pip3 install requests prettytable docopt colorama
下面开始构建属于自己的命令行列车时刻查询工具。
# coding: utf-8
"""命令行火车票查看器
Usage:
tickets [-gdtkz] <from> <to> <date>
Options:
-h,--help 显示帮助菜单
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
Example:
tickets 杭州 北京 2019-03-25
tickets -dg 杭州 北京 2019-03-25
"""
from docopt import docopt
def cli():
"""command-line interface"""
arguments = docopt(__doc__)
print(arguments)
if __name__ == '__main__':
cli()
根据官方文档说明,docopt需要1个必传参数和4个可选参数:
docopt(doc, argv=None, help=True, version=None, options_first=False)
doc是由字符串或者注释构成的命令行模块,格式如以上代码所示(doc could be a module docstring (doc) or some other string that contains a help message that will be parsed to create the option parser)。arguments,键为Usage和Options中选项,值为实际输入内容。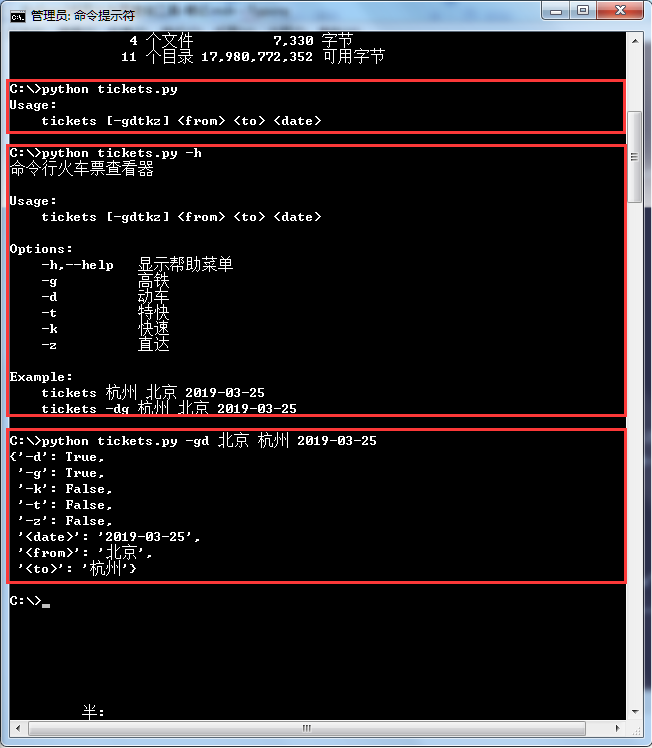
查火车票只能去12306,但是铁道部没有提供API,那么我们就不能查询了吗,答案是否定的。我们现在在网站上查询几次列车信息,寻找接口的蛛丝马迹。
在列车查询页面,然后打开浏览器调试模式(Windows下Chrome浏览器快捷键是F12),进入Network中,查看XHR,然后查询列车信息
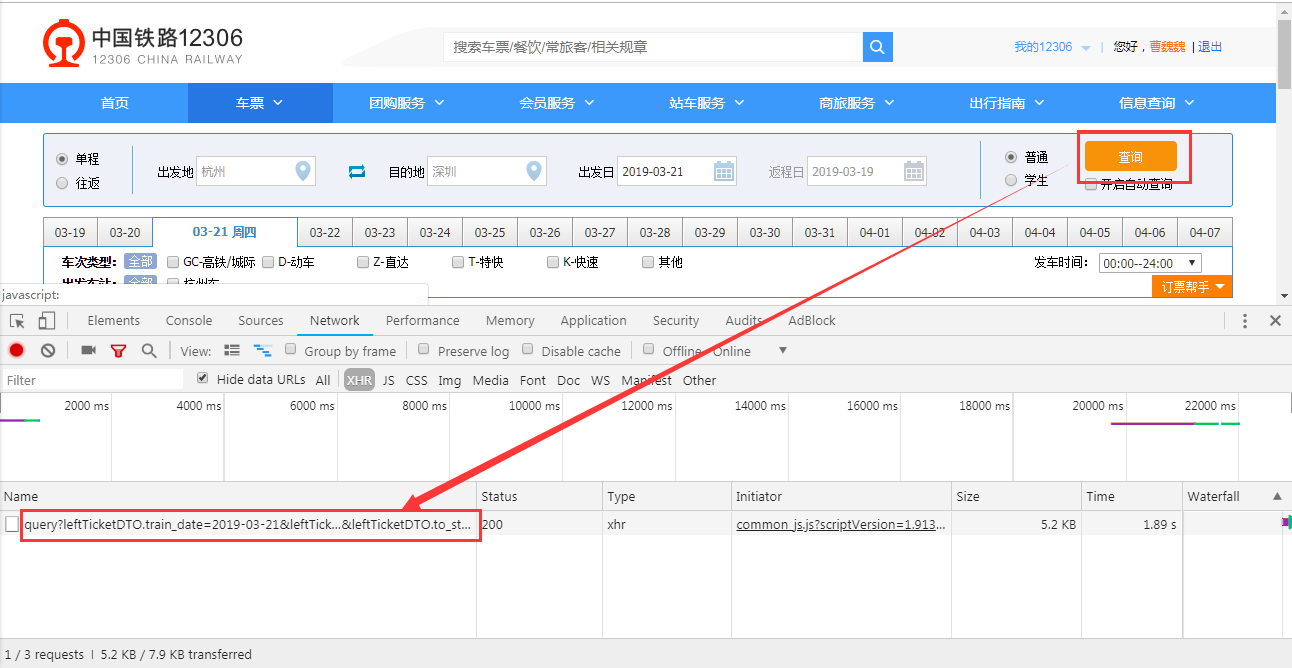
点击箭头指向的文件,我们可以看到在 Headers栏目中的Request URL中包括了查询的所有条件信息:出发地、目的地、出发日
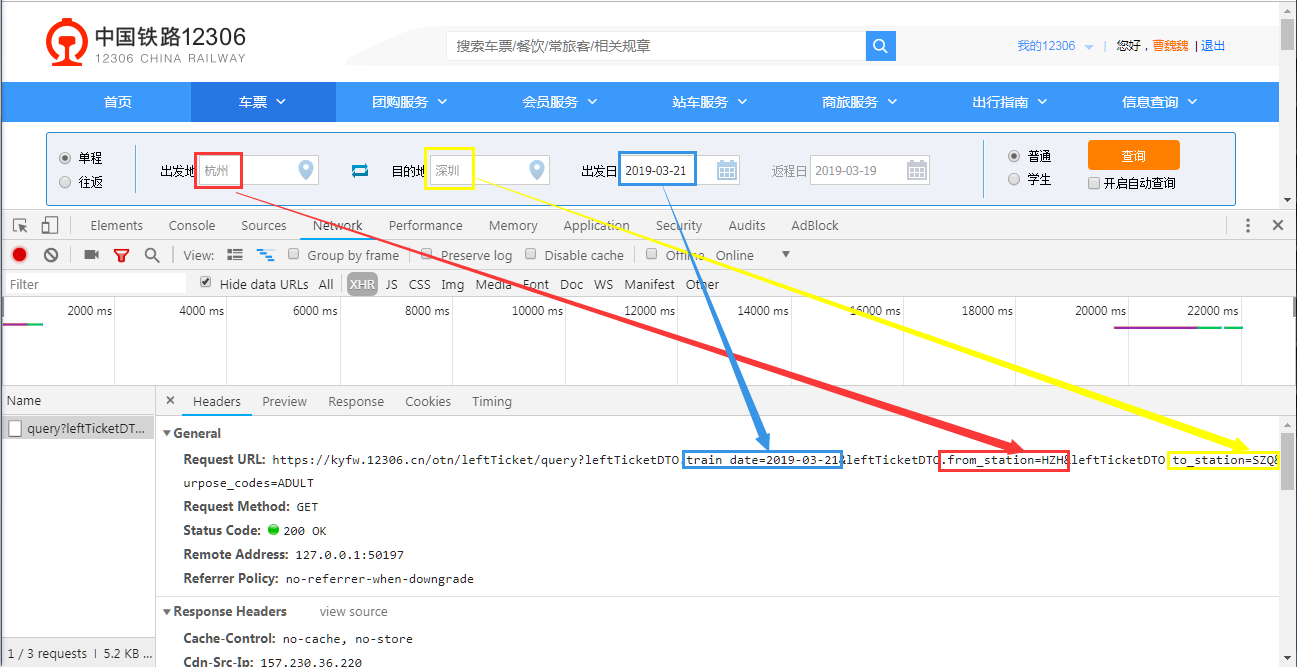
再点击Preview查看返回结果,这个就是查询到的列车时刻信息了
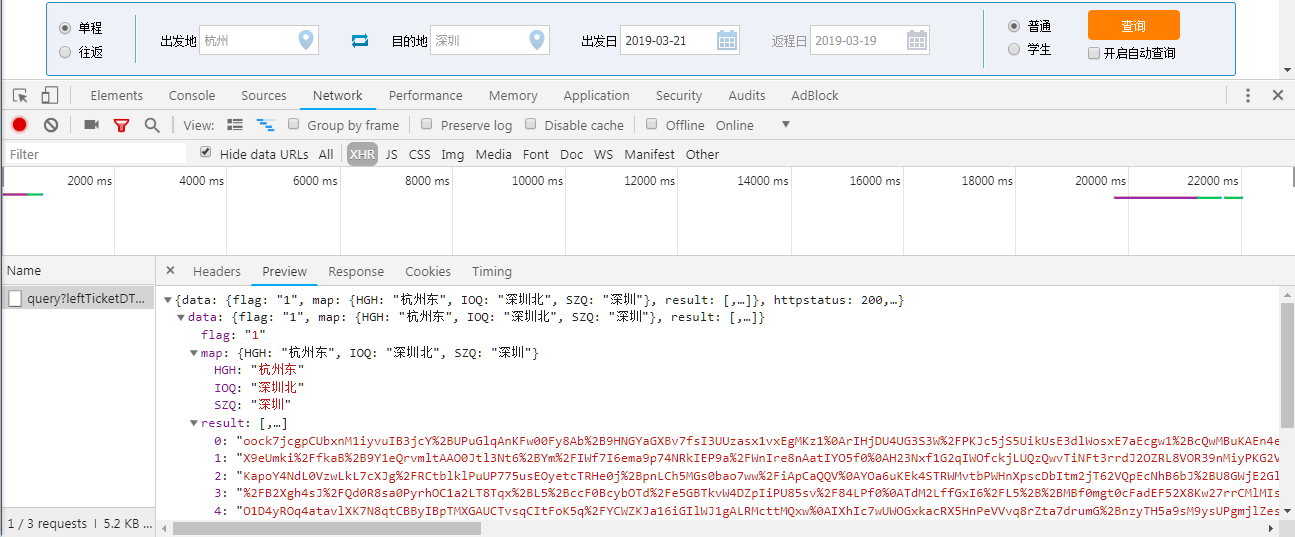
知道如何查询列车车次信息后,还有一个问题,就是我们输入的是中文车站名,接口处理的是英文车站代码,这个映射关系还不知道,需要继续查看页面加载的文件,寻找这个对应关系的文件,结果找到了如图文件
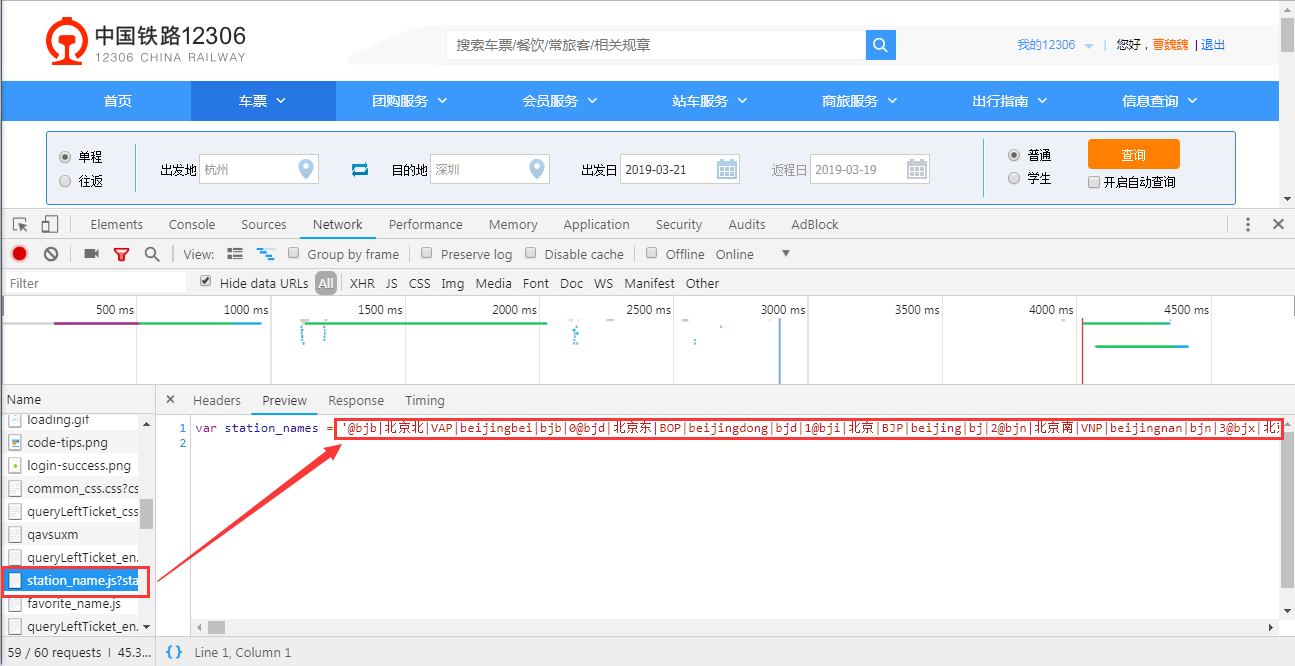
requests库接口信息分析完毕,下面用requests库进行实战。
# --coding: UTF-8--
import re, requests
from pprint import pprint
# 车站中英文文件URL
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9098'
# 使用requests库发起请求,获得响应的json文件
resp = requests.get(url)
# 对获得的响应文件使用正则表达式,获得车站中文名和英文代码组成的元祖构成的列表
stations = re.findall(r'([\u4e00-\u9fa5]+)\|([A-Z]+)', resp.text)
# 格式化输出车站
pprint(dict(stations), indent=4)
— stations 返回的结果如下图,是车站中文名和英文代码构成的元组组成的列表

— 使用 python parse_stations.py > stations.py命令并生成stations.py文件,车站文件内容为中文名和英文代码构成的字典,这样就可以导入stations.py文件后根据键(车站中文名)从字典中检索对应值(车站中文对应的英文代码)

回顾一下,在命令行界面输入的起始车站中文名和列车出发日期,这些信息都在arguments这个字典对象中,只需要根据输入的信息匹配车站英文代码,然后访问车次查询接口,这样就可以查询列车信息了
— 修改命令行函数cli中代码
def cli():
"""command-line interface"""
arguments = docopt(__doc__)
# 根据命令行用输入的起始车站名称、日期,查询stations中对应的英文代码
from_station = stations.get(arguments['<from>'])
to_station = stations.get(arguments['<to>'])
date = arguments['<date>']
# 发起请求查询车次信息
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT'.format(date, from_station, to_station)
r = requests.get(url)
# 将返回的json数据转为字典类型
# 其中车次信息在返回的字典键为data的值嵌套的字典中,其嵌套的键为result的值中
available_trains = r.json()['data']['result']
— 返回的车次结果信息如图所示

对获取的车次信息一头雾水,那么需要尝试继续在网站中寻找线索。一般来说,网站的js文件中会定义这些数据结构,并标注每个字段的含义,所以现在来寻找这样的js文件。
进入浏览器调试模式,查看源代码source。猜测是图中所示的文件可能包括车票信息,因为查询车次就是查询列车余票信息。
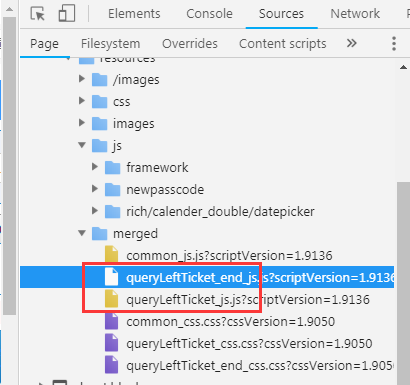
将压缩的js代码调整下格式,然后尝试搜索“硬座”与列车相关的信息关键词,结果找到了如下代码,这下知道坐席代码了:

继续寻找“硬座”,发现并没有更多有价值内容,然后尝试搜索“硬座”的键值“YZ”,发现关键代码:

完美,这段代码十分详细的介绍了车次信息中各个值的含义,我们再拿来和在12306查询到的车次信息比对发现完全正确,这样就可以解析车次信息了。
接下来使用类来封装获取的列车信息,整体思路是,通过类来处理页面爬虫获取的列车信息,并将数据清洗后展示出来,列车信息类TrainsInfo的代码如下:
class TrainsInfo:
def __init__(self, available_trains, from_to_stations, options):
"""
定义类用到的变量:列车信息,列车类型选项
available_trains:列车信息
fom_o_saions:起止车站,模糊匹配,例如杭州,杭州东等
options:列车类型选项
"""
self.available_trains = available_trains
self.from_to_stations = from_to_stations
self.options = options
@property
def trains(self):
for each_train in self.available_trains:
each_train_split = each_train.split('|')
train_code = each_train_split[3]#车次
if not self.options or train_code[0].lower() in self.options):
"""
显示符合条件的列车信息,即列车类型匹配g/d/z等 或者
不输入列车等级 也可查询
"""
trains = [train_code, #车次
each_train_split[6], #起点车站代码
each_train_split[7], #终点车站代码
each_train_split[8], #发车时间
each_train_split[9], #到达时间
each_train_split[10], #历时
each_train_split[11], #网上购票
each_train_split[26] if each_train_split[26] else '--', #无座
each_train_split[27] if each_train_split[27] else '--', #硬座
each_train_split[24] if each_train_split[24] else '--', #软座
each_train_split[28] if each_train_split[28] else '--', #硬卧
each_train_split[33] if each_train_split[33] else '--', #动卧
each_train_split[23] if each_train_split[23] else '--', #软卧
each_train_split[21] if each_train_split[21] else '--', #高级软卧
each_train_split[30] if each_train_split[30] else '--', #二等座
each_train_split[31] if each_train_split[31] else '--', #一等座
each_train_split[25] if each_train_split[25] else '--', #特等座
each_train_split[32] if each_train_split[32] else '--', #商务座
each_train_split[22] if each_train_split[22] else '--', #其他
]
yield trains
def print_train_info(self):
for train in self.trains:
print(train)
为了调用类,修改后的cli代码如下:
def cli():
"""command-line interface"""
arguments = docopt(__doc__)
from_station = stations.get(arguments['<from>'])
to_station = stations.get(arguments['<to>'])
date = arguments['<date>']
"""获取查询得到的列车车次及起止车站信息"""
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT'.format(date, from_station, to_station)
r = requests.get(url)
"""
available_trains 获取查询到的列车信息,返回值是车次信息列表
from_to_stations 获取起止车站信息,返回值是车站英文代码和车站中文构成的字典
options 获取从命令行输入的参数,将列表转为字符串,方便后续使用
"""
available_trains = r.json()['data']['result']
from_to_stations = r.json()['data']['map']
options = ''.join([key for key, value in arguments.items() if value != False])
TrainsInfo(available_trains, from_to_stations, options).print_train_info()
测试下输出的结果,输入python tickets.py 杭州 绩溪县 2019-03-30,可查询到如下列车信息:
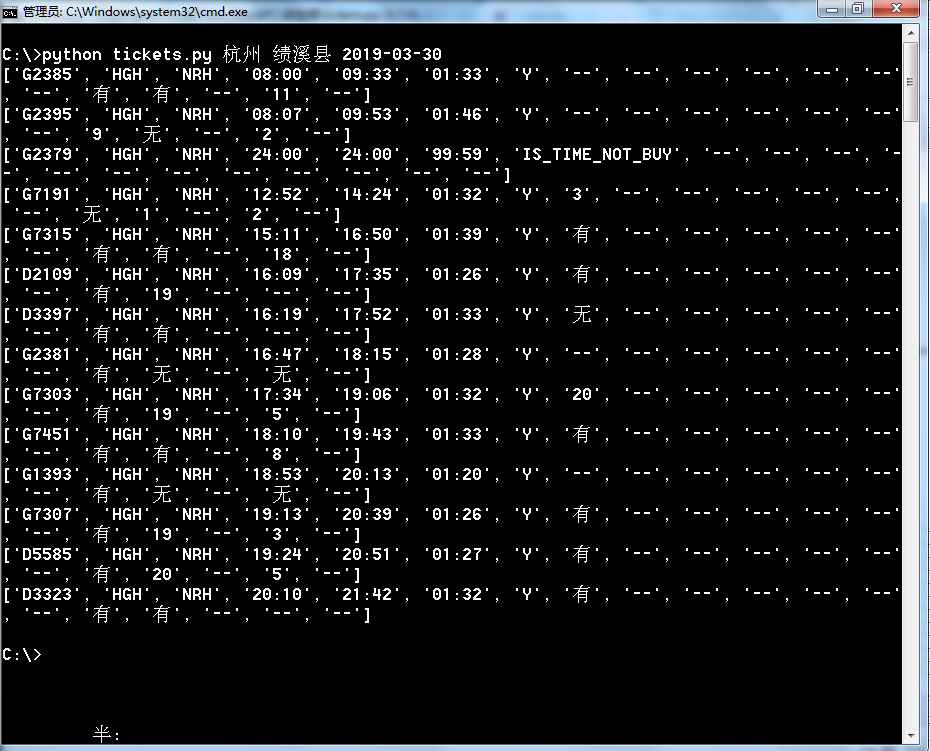
看一下12306的查询结果,比对一下,完全一致。
但是工作到这里并没有结束,这个输出界面太丑陋了,需要精致一些。使用prettytable库来将信息用表格形式输出,在调整些颜色即可。
调整列车信息打印函数,通过表格输出信息,在使用前需要引用prettytable库 import prettytable
def print_train_info(self):
# 创建表格
tb = prettytable.PrettyTable()
# 设置表格标题
tb.field_names = self.headers
for train in self.trains:
# 增加每行数据
tb.add_row(train)
print(tb)
列车信息类中需要对train信息进行颜色标识,整体代码修改后如下:
init()
class TrainsInfo:
headers = '车次 车站 时间 历时 有票 无座 硬座 软座 硬卧 动卧 软卧 高级软卧 二等座 一等座 特等座 商务座 其他'.split()
def __init__(self, available_trains, from_to_stations, options):
"""
定义类用到的变量:列车信息,列车类型选项
available_trains:列车信息
fom_o_saions:起止车站,模糊匹配,例如杭州,杭州东等
options:列车类型选项
"""
self.available_trains = available_trains
self.from_to_stations = from_to_stations
self.options = options
@property
def trains(self):
for each_train in self.available_trains:
each_train_split = each_train.split('|')
train_code = each_train_split[3]#车次
if not self.options or train_code[0].lower() in self.options:
"""
显示符合条件的列车信息,即列车类型匹配g/d/z等 或者
不输入列车等级 也可查询
"""
trains = [train_code, #车次
'\n'.join([Fore.GREEN + self.from_to_stations[each_train_split[6]] + Fore.RESET,
Fore.RED + self.from_to_stations[each_train_split[7]] + Fore.RESET]),
'\n'.join([Fore.GREEN + each_train_split[8] + Fore.RESET,
Fore.RED + each_train_split[9] + Fore.RESET]),
each_train_split[10], #历时
each_train_split[11], #网上购票
each_train_split[26] if each_train_split[26] else '--', #无座
each_train_split[27] if each_train_split[27] else '--', #硬座
each_train_split[24] if each_train_split[24] else '--', #软座
each_train_split[28] if each_train_split[28] else '--', #硬卧
each_train_split[33] if each_train_split[33] else '--', #动卧
each_train_split[23] if each_train_split[23] else '--', #软卧
each_train_split[21] if each_train_split[21] else '--', #高级软卧
each_train_split[30] if each_train_split[30] else '--', #二等座
each_train_split[31] if each_train_split[31] else '--', #一等座
each_train_split[25] if each_train_split[25] else '--', #特等座
each_train_split[32] if each_train_split[32] else '--', #商务座
each_train_split[22] if each_train_split[22] else '--', #其他
]
yield trains
这里面用到了colorama命令行着色工具,使用前需要引入库 from colorama import init, Fore,然后初始化init() 并设置颜色Fore.GREEN Fore.RED Fore.RESET
本项目最核心知识点在于requests库的使用,难点在于如何分析js文件寻找车站和英文关系对应以及列车车次信息获取后如何解析。
其他的知识点还有yield使用,@property装饰器,dicopt命令行界面以及prettytable表格输出colorama表格上色。
详细代码请查阅:https://github.com/elicao/12306query-tickets
Originally published
Latest update April 27, 2020
Related posts :